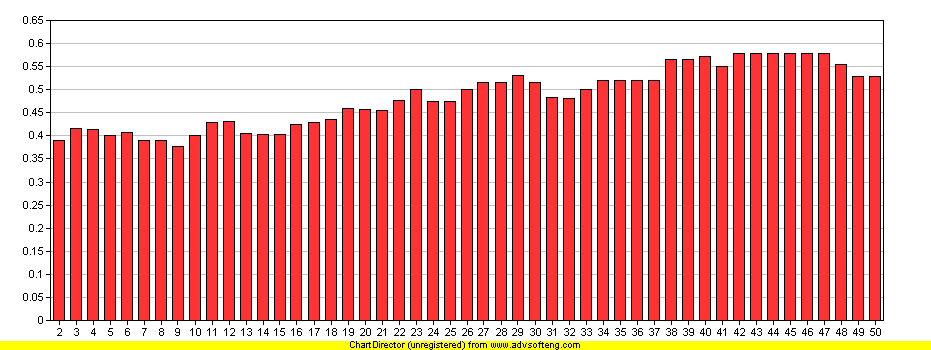
Candidate Base 左右 |R| 的變化對應 與 Real Terms 的左右變化圖表.
** 並非將所有斷句處當做一種狀況, 遇到斷句處, R值+1, 借以提高斷句資訊的強度.
Y : Real Terms |R| >=n / Candidate Terms |R| >= n
X : n (|R|數量的變化, 僅取 n > 2 and n < 50)
[圖 1] Candidate Base 詞條左側 |R| 值對應 Real Terms 的變化
[圖 2] Candidate Base 詞條右側 |R| 值對應 Real Terms 的變化
上圖 1 實際參數
X
All Candidates
^ Mullers
Y
上圖 2 實際參數
X
All Candidates
^ Mullers
Y
[Max: 詞條左右出現各種不同的可能(|R|)中, 其中次數最多的是多少次]
一般化: 將 Max / fx, fx 是該詞條的總數
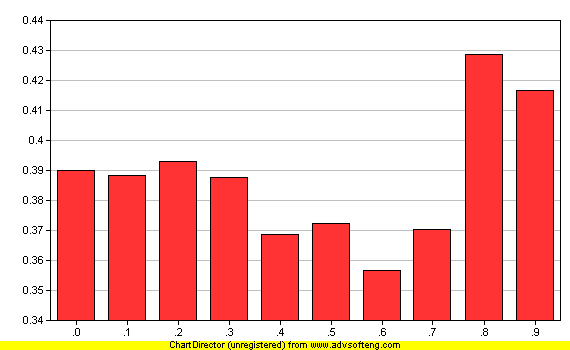
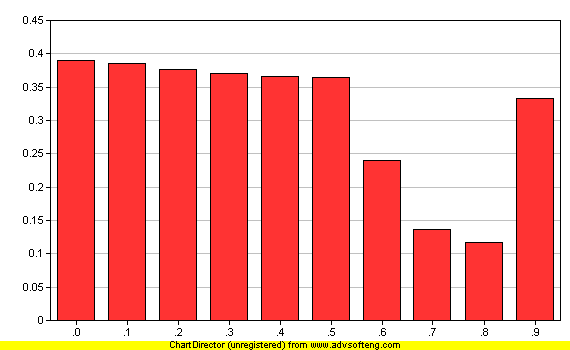
Candidate Base 左右 Max/fx 的變化對應 與 Real Terms 交集詞條的變化圖表.
** 所有的斷句處 Max 值均不累計, 斷句處的 Max 值永遠為 1, 借以降低關聯性資訊.
Y : Real Terms 的詞條的Max/fx / Candidate Base 的 Max/fx
X : Max/fx 數量的變化, 間隔 0.1
[圖 5] Candidate Base 詞條左側 Max/fx 值對應 Real Terms 的變化
[圖 6] Candidate Base 詞條右側 Max/fx 值對應 Real Terms 的變化
上圖 5 實際參數
X
All Candidates
^ Mullers
Y
上圖 6 實際參數
X
All Candidates
^ Mullers
Y
[Algorism AEc]
AEc = fx / fy + fz - fx
Ex:
string: 中華佛學研究所
fx = No. of 中華佛學研究所
fy = No. of 中華佛學研究
fz = No. of 華佛學研究所
以 0.01 為間隔, 取一百段的 AEc 值(0.01~1.0)
計算 Candidate Base 詞條中的 AEc 值 >= 上述區段時, 與 Real Terms 比對的交集結果